Deep Learning
import tensorflow as tf
# Get the GPU device name.
device_name = tf.test.gpu_device_name()
# The device name should look like the following:
if device_name == '/device:GPU:0':
print('Found GPU at: {}'.format(device_name))
else:
raise SystemError('GPU device not found')
The below illustration demonstrates adding two special token for each sentence tokens.
I'll be using BertForSequenceClassification. This is the normal BERT model with an added single linear layer on top for classification that I will use as a text classifier. The entire pre-trained BERT model and the additional untrained classification layer is trained on our specific task.
Exploring the Use of Text Classification in the Legal Domain
Introduction
Text classification methods have been successfully applied to a number of NLP tasks and applications ranging from plagiarism
and pastiche detection to estimating the period in which a text was published. In this paper I discuss the application of text
classification methods in the legal domain which, to the best of our knowledge, is relatively under-explored and to date its application has been mostly restricted to forensics.
BERT pushed the state of the art in Natural Language Processing (NLP) by combining two powerful technologies:
- It is based on a deep Transformer network. A type of network that can process efficiently long texts by using attention.
- It is bidirectional. Meaning that it takes into account the whole text passage to understand the meaning of each word.
Setup
Google Colab offers free GPUs and TPUs! Since we'll be training a large neural network it's best to take advantage of this (in this case we'll attach a GPU), otherwise training will take a very long time. You can follow the following steps:import tensorflow as tf
# Get the GPU device name.
device_name = tf.test.gpu_device_name()
# The device name should look like the following:
if device_name == '/device:GPU:0':
print('Found GPU at: {}'.format(device_name))
else:
raise SystemError('GPU device not found')
Dataset - 900 labeled judgments
There are 999 judgments in the Judgments folder. The Mapping.csv file provides the corresponding Area of Law of 899 judgments.
The remaining 100, which are indicated by ‘To be Tested’ in the Area of Law column, will be used for testing.
All these documents are under my github : number-identify/Text_Classification session.
Here is the link to my github
I use count plot to see how many area of law. As we can see that 'Civil Procedure' is the most common area of law. Some area of law only appear in two Judgment.
However, it is OK as I will solve this inbalance problem in the later session.
 In this report we first explore the data set, drop useless information in the data and explore the correlation between the features and the label.
Then for classification we use Logistic regression and two tree based methods (Random Forest and XGBoost) to predict whether the customer spent money on the website. Cross validation are used for selecting hyper parameters for each model and we compare their performance by Mean Square Error.
In this report we first explore the data set, drop useless information in the data and explore the correlation between the features and the label.
Then for classification we use Logistic regression and two tree based methods (Random Forest and XGBoost) to predict whether the customer spent money on the website. Cross validation are used for selecting hyper parameters for each model and we compare their performance by Mean Square Error.
For regression we try linear regression (including feature selection), tree based methods (bagging and boosting) and neural network solution. We hope to get a much smaller mean square error compared to the variance of the data.
Then we use the best models from both classification (XGboost) and regression (ridge regression) to build a combined model, and improve the result by using predicted data to train the regression model. The new hybrid model has a MSE of 1.11, which shows a good performance. We formally write down the algorithm we choose to use in the fifth part.
Tokenization & Input Formatting
In this section, I'll transform our dataset into the format that BERT can be trained on.
BERT Tokenizer
To feed our text to BERT, it must be split into tokens, and then these tokens must be mapped to their index in the tokenizer vocabulary.
The tokenization must be performed by the tokenizer included with BERT. I'll be using the "uncased" version here.
Here is the example of the tokenization output.
Original: Our friends won't buy this analysis, let alone the next one we propose.
Tokenized: ['our', 'friends', 'won', "'", 't', 'buy', 'this', 'analysis', ',', 'let', 'alone', 'the', 'next', 'one', 'we', 'propose', '.']
Token IDs: [2256, 2814, 2180, 1005, 1056, 4965, 2023, 4106, 1010, 2292, 2894, 1996, 2279, 2028, 2057, 16599, 1012]
Required Formatting
We are required to:
- Add special tokens to the start and end of each sentence.
- Pad & truncate all sentences to a single constant length.
- Explicitly differentiate real tokens from padding tokens with the "attention mask".
The below illustration demonstrates adding two special token for each sentence tokens.
Figure1

Figure2
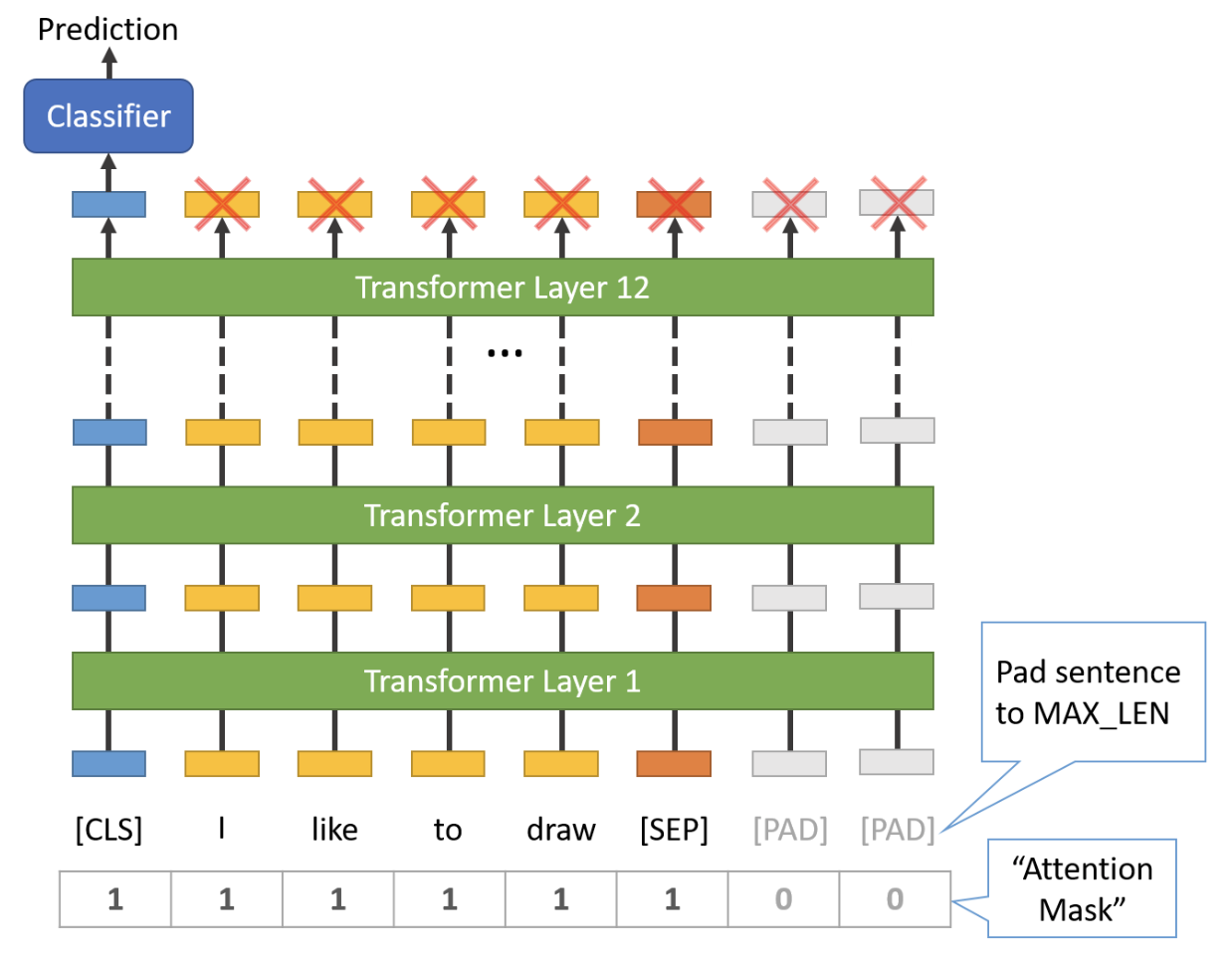
Sentence Length & Attention Mask
The sentences in our dataset obviously have varying lengths, so how does BERT handle this by adding two constrains:
- All sentences must be padded or truncated to a single, fixed length.
- The maximum sentence length is 512 tokens.
Create chunks for long text
Since the maximum length of a token list is 512, therefore for a long text, I will truncate it into several token list with length equals to 512. For classification tasks, we must prepend the special [CLS] (101) token to the beginning of every sentence and the special [SEP] (102) token to the end of every sentence. Therefore, for each Judgement, it is splited into several chunks with 512 tokens in each chunk. therefore, the orginal 899 Judgments have been split into 8614 chunks. Each chunk obeys the rule of input of BERT model. In the final evaluation and test part, when we get the label for each chunk, we need aggragate all the chunk label and choose the most frequent label as the labe for the whole Judgment text.
Train Classification Model
I first want to modify the pre-trained BERT model to give outputs for classification, and then continue training the model on my dataset until that the entire model, end-to-end, is well-suited for this task. The huggingface pytorch implementation includes a set of interfaces designed for a variety of NLP tasks. Though these interfaces are all built on top of a trained BERT model, each has different top layers and output types designed to accomodate their specific NLP task. Here is the current list of classes provided for fine-tuning:
- BertModel
- BertForPreTraining
- BertForMaskedLM
- BertForNextSentencePrediction
- BertForSequenceClassification - The one I'll use.
- BertForTokenClassification
- BertForQuestionAnswering
- The documentation for these can be found under here.
I'll be using BertForSequenceClassification. This is the normal BERT model with an added single linear layer on top for classification that I will use as a text classifier. The entire pre-trained BERT model and the additional untrained classification layer is trained on our specific task.
Evaluation the Result
The training accuracy is evaluated as a graph below:
 I took the average of the evaluation accuracy for each batch, the average accuracy is 69% for a chunk.
However, as I said before, we should take the most frequent label (area of law) to obtain the final label for Judgment.
After aggragate the chunk labels, the final accuracy is modified to 78%.
I took the average of the evaluation accuracy for each batch, the average accuracy is 69% for a chunk.
However, as I said before, we should take the most frequent label (area of law) to obtain the final label for Judgment.
After aggragate the chunk labels, the final accuracy is modified to 78%.
Final Conclusion
In general NLP approach will be better than other traditional machine learning approaches. In general if the dataset is not too large, then machine learning models like Naive Beysian, SVM usually performs quite good, because the algorithm are designed for text classification. However, when the dataset is large, the NLP methods out-perform these traditional machine learning, as it is quicker and it is built based on the text contents. However, more work needs to be done to optimize state-of-the-art methods for the legal domain.