NLP



Topic Modeling for My Business Feedback survey
Executive Summary
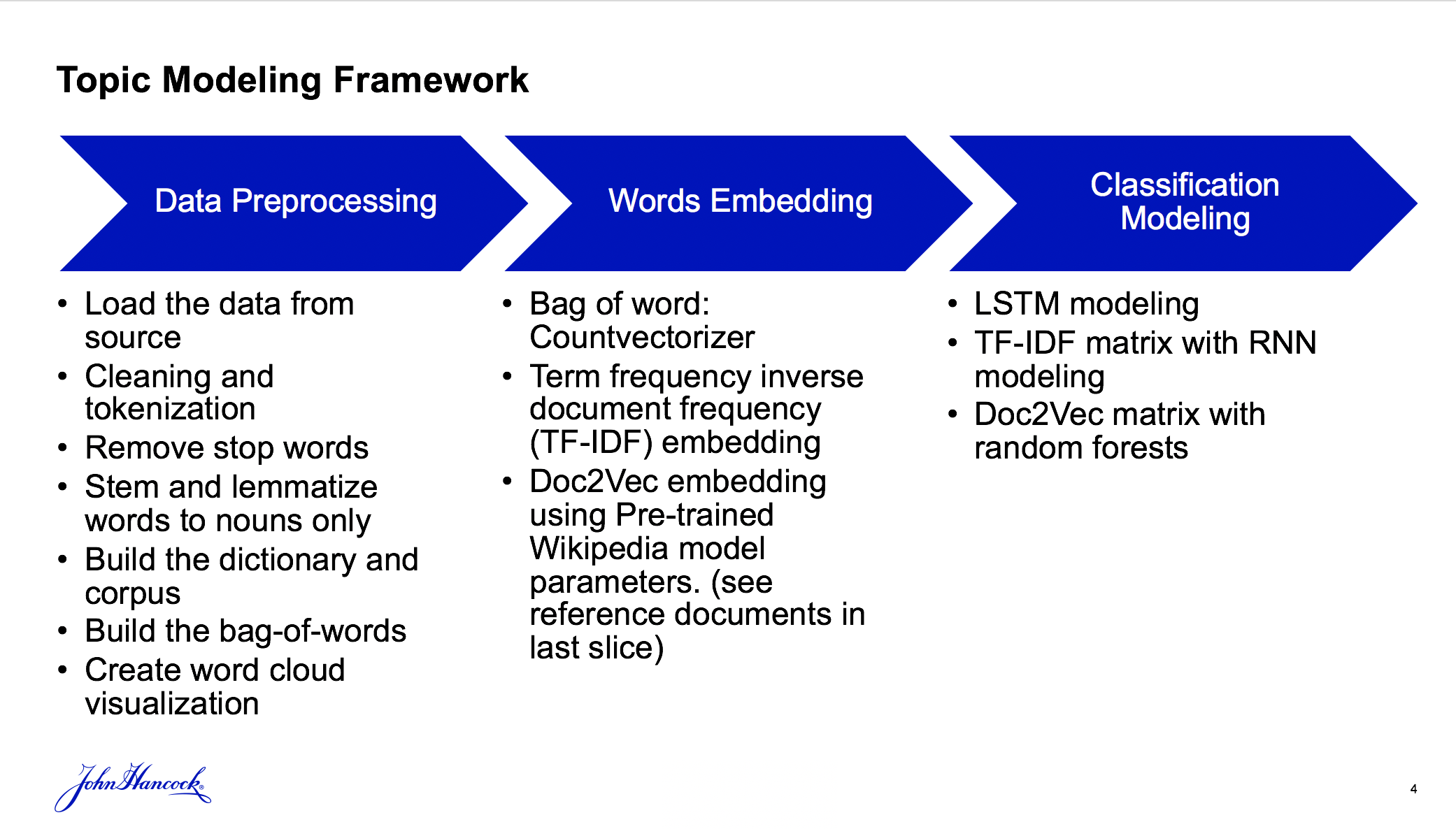
In this project, my object is to build a text analytics/topic modeling capability with the data sources from Sales Hub Feedback Data: My Business Feedback. I retrieve a some proportion from the data set (1%), and build a trial on them. The data is a csv file with 293 feedbacks and 760 unique words after preprocessing. It also includes manual assignment of a topic to each survey response. In general, the topic modeling framework including:
- Data Preprocessing
- Word cloud
- Words embedding by vectors
- Classification Modeling
- Classification Model Analysis
Data Preprocessing
After loading the data from source (csv file or python library) I determined the data structure of the source and utilize only the relevant text data. In the cleaning and tokenization process,
remove all missing comments and categories, newline characters, digits, and punctuations to identify and retain only the words or tokens. Besides, I remove stop words, stop words are common words
that do not necessarily provide valuable information to the NLP task at hand. Examples: I, me, myself, he, she, what, which, this, the, etc. However, stopwords are not enough for My Business Feedback Survey,
I also add self-defined stop words. Example: company name, company, insurance, and other words that are totally iirelevant to the topic.
After getting rid of stop words, the words in topic texts are not in the orinigial form. Sometimes, to unite all the words into one defined format could increase the prediction and reduce the computation time.
Therefore, it is time to stem and lemmatize words. In this case, I choose to convert all words into base format, so I remove derivational affixes and endings and return the base or dictionary form of a word.
Next I build the dictionary for corpus and each word in the vocabulary is assigned a word ID. Next, I create word cloud visualization base on the bag-of-words are the collection of all tokens and token frequency.
The word cloud is the following: From the picture, word like 'website', 'information', 'can't', 'access', 'online' are highly frequently, which means mnost of users' feedbacks are about "online website".

Since in the excel file, I am given some manually assigned topic for each piece of feedback, let's take a look at how the feedbacks are divided.
There are 7 topics, namely \(error/fail, usability, service, functionality, product/industry, login/authenticate, and other\). Let's draw a histogram of the frequency of these topics. From the graph,
the frequency of these manually added topics is quite imbalanced. Error/fails make up of almost half of the total topics.

Word Embedding Methods
Bag of Words
The approach is very simple and flexible, and can be used in a myriad of ways for extracting features from documents. A bag of words is a representation of text that describes the occurrence of words within a document. It involve two things: a vocabulary of known words and a measure of the presence of known words. Any information about the order or structure of wor.ds in the document is discarded. The model is only concerned with whether known words occur in the document, not where in the documents. Sparse vectors require more memory and computational resources when modeling he vast number of positions or dimensions can make the modeling process very challenging for traditional algorithms.
Term Frequency Inverse Document frequency
With TF-IDF, words are given weight. It measures relevance, not frequency. That is, wordcounts are replaced with TF-IDF scores across the whole dataset. First, TF-IDF measures the number of times that words appear in a given document (that’s “term frequency”). But because words such as “and” or “the” appear frequently in all documents, those must be systematically discounted. That’s the inverse-document frequency part. The more documents a word appears in, the less valuable that word is as a signal to differentiate any given document. That’s intended to leave only the frequent AND distinctive words as markers. Each word’s TF-IDF relevance is a normalized data format that also adds up to one.
Doc2Vec
Doc2vec modified the word2vec algorithm to unsupervised learning of continuous representations for larger blocks of text, such as sentences, paragraphs or entire documents. Since Saleshub dataset only has limited comments, it is better to skip building embedding files and use pre-trained doc2vec embedding file for representing docs as vectors. For example: Wikipedia doc2vec model combined with DBOW (distribution bag od words) algorithm If you want to see pre-train model on Wikipedia, please see reference document Pre-Trained Model . In this example, I use 300 dimension in feature vectors, in other words, each of the sentence will be converted into a 300 dimentional vector.
Topic Modeling Framework
Topic Modeling with LSTM
Long Short Term Memory networks – usually just called “LSTMs” – are a special kind of RNN, capable of learning long-term dependencies.
Use LSTM embedding method to vectorize sentences by building word dictionary and represent each word by word index in the dictionary.
The next step is to decide what information we’re going to throw away and store in the cell state. This can be accomplished in the LSTM layer.
Finally I run a sigmoid layer which decides what parts of the call state we are going to output.
Set epoch as 20 and batch size as 32.

In the graph, the training loss and the testing loss is declining. Training accuracy increases while test accuracy drops after reaching the peak.
The result is not stable and could be explained that LSTM model is suitable for large dataset and the sample data from sales hub comments only has limited data.
TF-IDF with LSTM
If I try to use TF-IDF matrix as input in LSTM model, the training and testing remain the same. It still needs further improvement.
Doc2vec with Random Forest Classification
First we factorize class labels into integers and use randomizedSearchCV to tune parameters in the classification model. Rebuild Random Forest with best parameters and use ‘gini’ as criterion. The following is the tuned parameter:
- 'n_estimators': 683
- 'min_samples_split': 10
- 'min_samples_leaf': 2,
- 'max_features': 'sqrt’
- 'max_depth': 10
- 'bootstrap': False
Latent Dirichlet Allocation (LDA)
Latent Dirichlet Allocation (LDA) is a “generative probabilistic model” of a collection of composites made up of parts. It is the widely used technique for topic modeling.
LDA is based on the Dirichlet process.
The Dirichlet process is commonly used in Bayesian statistics in situations where we suspect there is clustering among random variables, but we do not know how many clusters there are,
nor which random variables belong to which cluster. In other words, we want to treat the assignment of the random variables to clusters as a random variable itself which can be estimated from the data.
We do not know the number of topics that are present in the collection of documents and the documents that belong to each topic.
Topics can be seen as a distribution of all words or tokens in the vocabulary.
A document is seen as a distribution of topics.
First utilize gensim.models.ldamodel.LdaModel function of the Gensim LDA implementation and combined with
the dataset in bag-of-words form from data preprocessing. In the following step, I will show you how to construct a LDA model.
Step1: We could create a baseline model to determine the Lda Model function parameters that guarantee model convergence.
- Set num_topics to 20 or higher
- Set chunksize to the nearest hundred or thousand of the number of documents in the corpus.
- Set alpha and eta parameters to “auto”
- Model convergence is determined by plotting the model perplexity vs the number of training epochs or iterations. The model has converged when the perplexity is already very low and does not change anymore after many epochs or iterations.
- Perplexity is a measurement of how well a probability distribution or probability model predicts a sample
- Using the same parameters as the baseline model, train models with topics from 2 to 20 (or more) and plot the coherence score of each model.
- Coherence of a topic is a measure of the degree of semantic similarity between its high scoring words. These measurements help distinguish between topics that are human interpretable and those that are artifacts of statistical inference.
- Choose the number of topics of the model with the highest coherence score.
- Topic Prevalence – proportional to size of the area of the circles. Numbers in the circle are sorted by most popular (1) down to least popular (higher numbers).
- Topic Similarity – proportional to the distance between circles
- Topic Interpretation – use the top most salient terms to make sense of each of the topics
- Identify the most relevant topics in each of the document
- Identify the distribution of the topics in all of the documents
My Business FeedbackIdentified most relevant topics in the documents using an unsupervised model; showing % of responses assigned to each topic.
Assigned a name to the 8 topics identified by the model using the dominant words under each topic.
The following are the chosen four pieces of Word clouds of top keywords for each topic. Actually, topics do not line up one to one meaning there is potentially due to various reason (e.g. high overlap in the original topics) – Besides, i only take a small number of feedback from the data, therefore, work is needed to refine this framework like increase the number for feedbacks.
Model Comparison and Limitation Summary
In this project, I use 3 surprised models, that is based on the manually assigned topics, I then create topic for feedbacks that are not assigned topics.
The models includes Pure LSTM model with 20 epochs and 32 batche, TF-IDF + LSTM model and Doc2Vec + Random forest.
LSTM performs the best among three models. Since the dataset is very small, we should not use complex RNN structure.
Doc2Vec + random forest should perform well when the dataset is balance, but they still need further work.
Standard classifier algorithms like Random Forest has a bias towards classes which have number of instances. It tends to only predict the majority class data.
The features of the minority class are treated as noise and are often ignored. Thus, there is a high probability of misclassification of the minority class as compared to the majority class.
This type of situation can be handled using techniques based on over-sampling of minority class.
Till now, we only try supervised models.
We could also try unsupervised models like LDA, this is a more common approach in topic modeling.
References