Machine Learning
In the end, we will use the fmin function from the hyperopt package to minimize our objective through the space.
When we take a look at the objective function, the evaluation metric is ROC_AUC score. as mentioned above, since we are using fmin and want to maximize ROC_AUC score, the loss we are using here -Roc_Auc_Score.
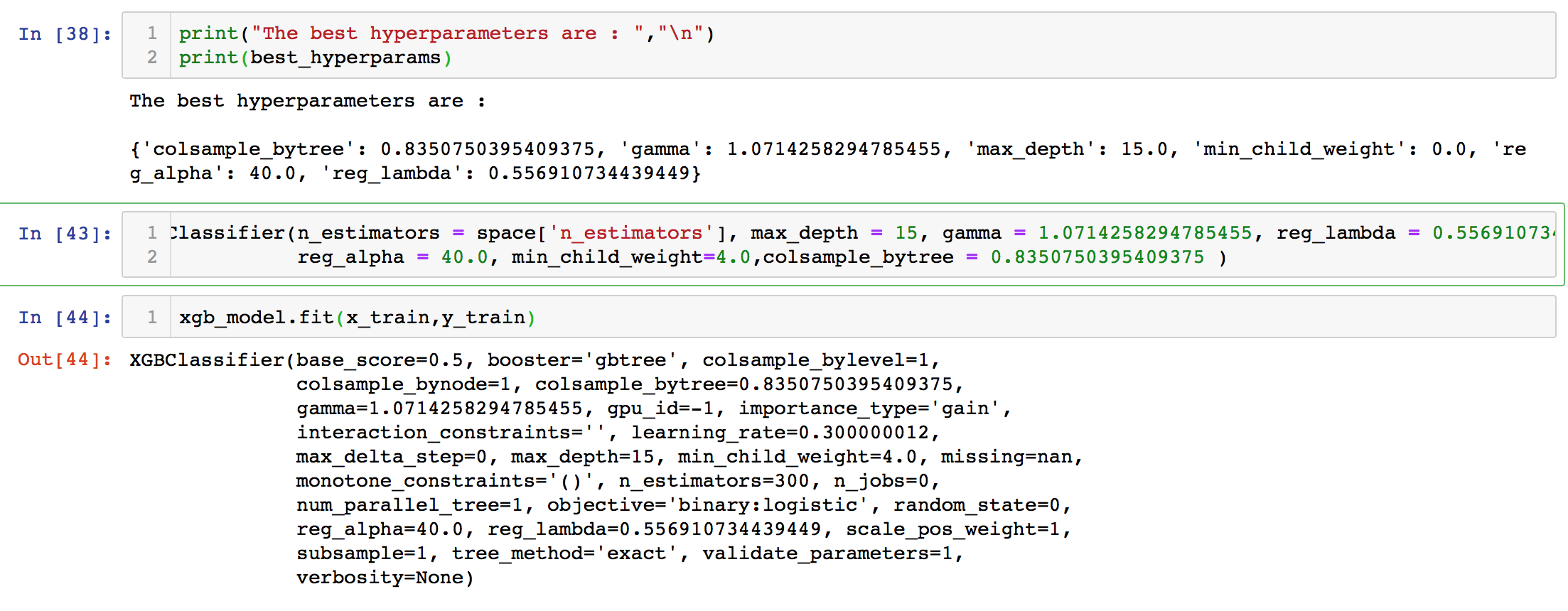
Now we can retrain our XGboost algorithm with these best params, and we are done.
Exploring Hyperopt parameter tuning
Abstract
Hyperparameter tuning can be a bit of a drag. GridSearch and RandomSearch are two basic approaches for automating some aspects of it. GridSearch is quite throughout but on the other hand rigid and slow. Rigid in only exploring specific set of exact parameter values, and slow in trying every combination, which quickly becomes a large set. RandomSearch explores variants faster but not very systematically, and also focuses on a similar strict specification of search-space.
Another approach is used by optimization frameworks/libraries such as Hyperopt. To me, it seems to combine some of the best of both, with random initializations leading to more guided search towards the promising areas. It also uses a more relaxed definition of the search-space in form of distributions vs exact values.
Introduction
To explain how hyperopt works. I will be working on a healthcare dataset from a Kaggle project. This dataset predicts the likelihood to purchase vehicle insurance given the information about customers from a healthcare company.
Just like medical insurance, there is vehicle insurance where every year customer needs to pay a premium of certain amount to insurance provider company so that in case of unfortunate accident by the vehicle, the insurance provider company will provide a compensation (called ‘sum assured’) to the customer.
Building a model to predict whether a customer would be interested in Vehicle Insurance is extremely helpful for the company because it can then accordingly plan its communication strategy to reach out to those customers and optimise its business model and revenue.
Now, in order to predict, whether the customer would be interested in Vehicle insurance, we have information about demographics (gender, age, region code type), Vehicles (Vehicle Age, Damage), Policy (Premium, sourcing channel) etc.
Data Modeling and Evaluation
Here I will show how to use Hyperopt to tune hyprerparameters. Since this project is to classify whether a potential customer will purchase vehicle insurance, I will apply Hypteropt on XgBoost and LightGbm models.
While trying to run Hyperopt, we will need to create two python objects:
- An objective function : The objective function takes the hyperparameter space as the input and returns the loss. Here we call our objective function objective
- A dictionary of hyperparams : We will define a hyperparam space by using the variable space which is actually just a dictionary. We could choose different distributions for different hyperparameter values.
In the end, we will use the fmin function from the hyperopt package to minimize our objective through the space.
Part1: Create the objective functions
Here we create an objective function which takes as input a hyperparameter space:
- We first define a classifier, in this case, XGBoost. Just try to see how we access the parameters from the space. For example space[‘max_depth’]
- We fit the classifier to the train data and then predict on the cross-validation set.
- We calculate the required metric we want to maximize or minimize.
- Since we only minimize using fmin in hyperopt, if we want to minimize logloss we just send our metric as is. If we want to maximize accuracy we will try to minimize -accuracy
Figure 1
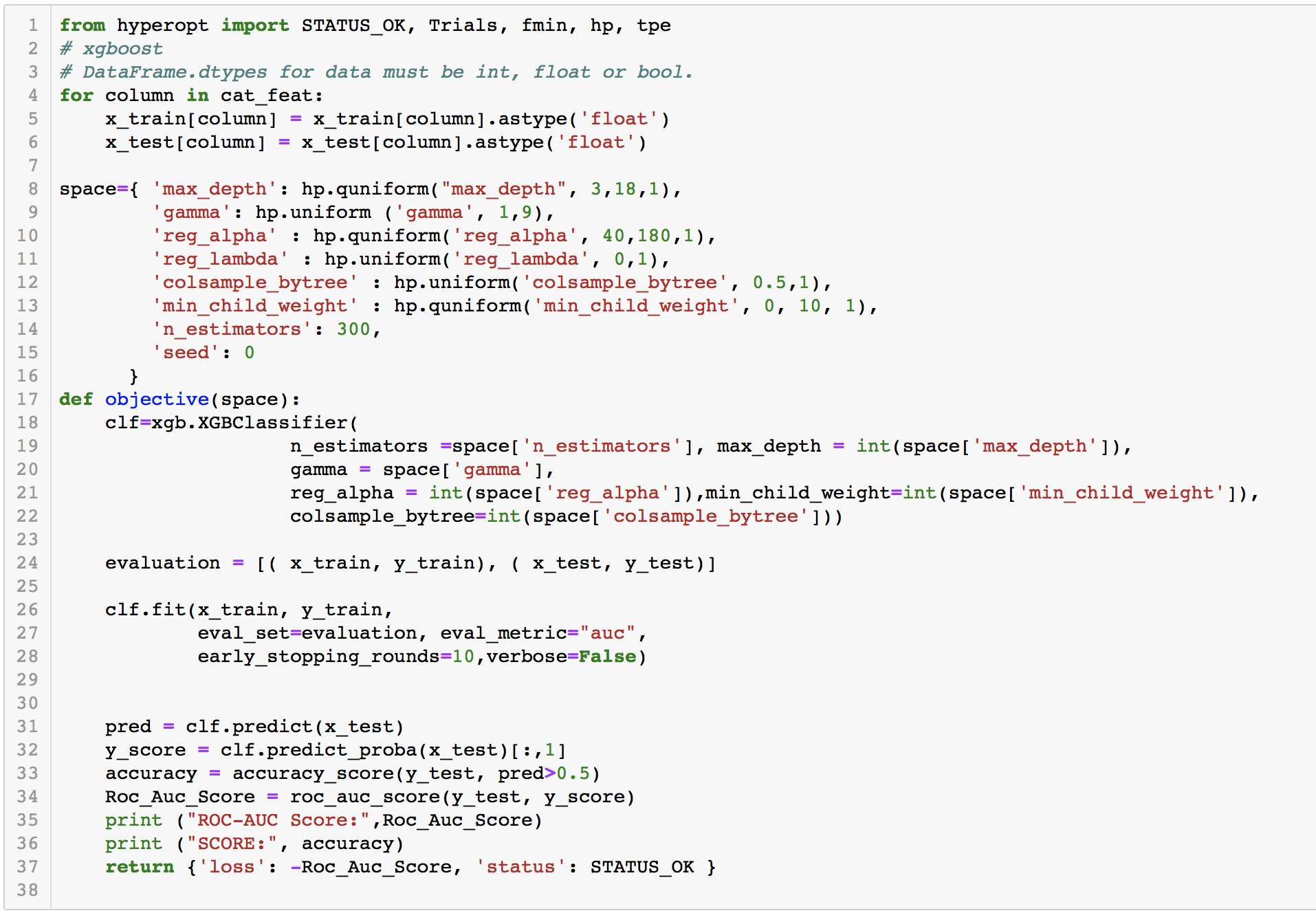
Part2: Create the Space for your classifiern
Now, we create the search space for hyperparameters for our classifier.
To do this, we end up using many of hyperopt built-in functions which define various distributions.
As you can see in the code above, we use uniform distribution between 1 and 9 for our gamma hyperparameter. We also give a label for the gamma parameter 'gamma'. You need to provide different labels for each hyperparam you define. I generally use my parameter name to create this label.
You can also define a lot of other distributions too. Some of the most useful stochastic expressions currently recognized by hyperopt’s optimization algorithms are:
- hp.choice(label, options) — Returns one of the options, which should be a list or tuple.
- hp.randint(label, upper) — Returns a random integer in the range [0, upper).
- hp.uniform(label, low, high) — Returns a value uniformly between low and high.
- hp.quniform(label, low, high, q) — Returns a value like round(uniform(low, high) / q) * q
- hp.normal(label, mu, sigma) — Returns a real value that’s normally-distributed with mean mu and standard deviation sigma.
Part3: And finally, Run Hyperopt
Once we run the following code, we get the best parameters for our XgBoost model. Turns out we achieved an accuracy of 86% by just doing this on the problem. Since I set max_evals equals to 100, therefore the objective function will run for 100 times to find the minimal ROC_AUC score. The process is optimized.
Figure 3
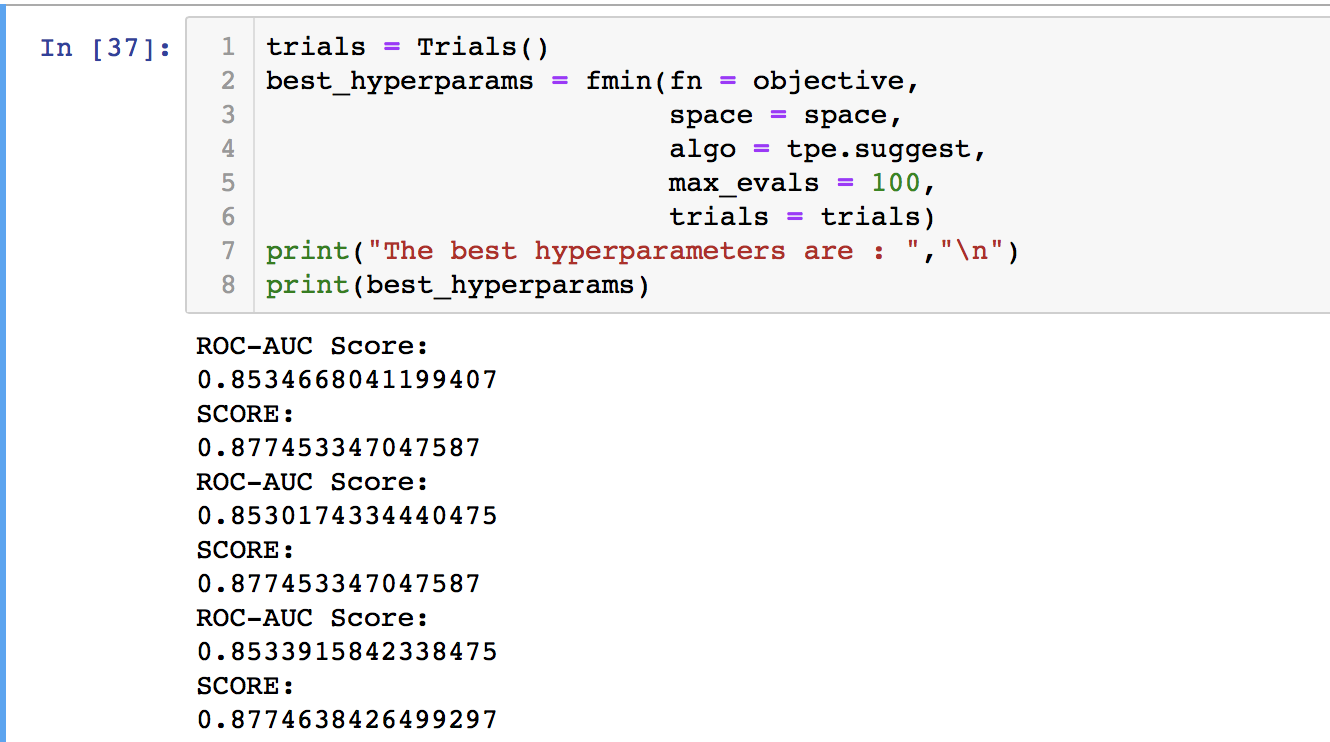
Figure 4
Now, either we can manually test the Sensitivity and Specificity for every threshold or let sklearn do the job for us. Sklearn has a very potent method roc_curve() which computes the ROC for your classifier in a matter of seconds! It returns the FPR, TPR, and threshold values.
The AUC score can be computed using the roc_auc_score() method of sklearn.
It is evident from the plot that the AUC for the XgBoost ROC curve is higher than Random Guess (which is a diagonal line from bottem left to top right). Therefore, we can say that Xgboost did a better job of classifying the positive class in the dataset.
Figure 5
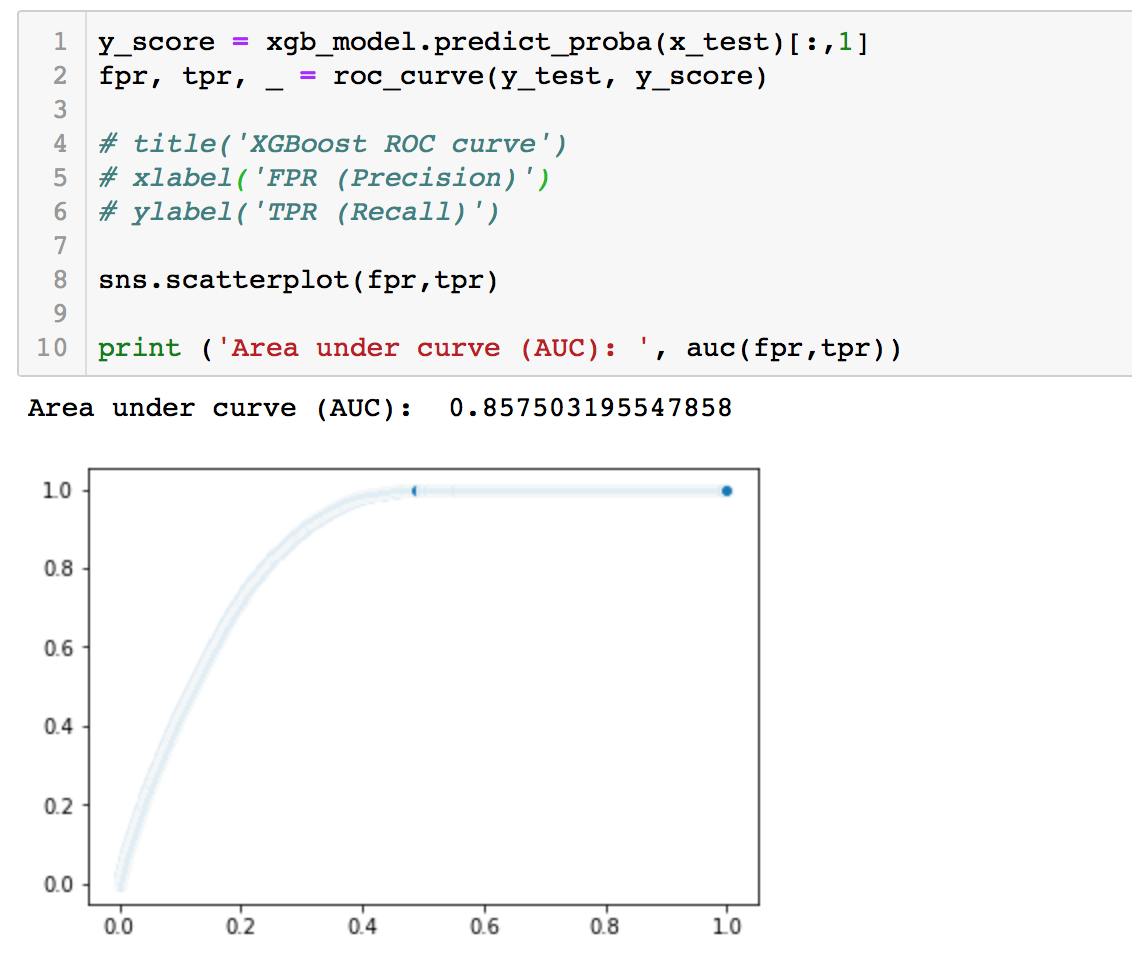
Applying Hyperopt to LightGBM Model
We already tried Hyperop on XgBoost model, now we can move on to lightGBM model. Similarly, the total logic is the same, but I use a different loss function here, instead of using ROC_AUC score only, I choose to use ROC_AUC score combined with K-Fold validation. As we can see in figure 6, I adopt 10-Fold validation. I want to maximize the average score of the ROC_AUC score. Therefore, in the objective function, it returns negtive score as the objective loss.
Figure 6

Similarly, I adopt Hyperopt to design space and use fmin functoin to optimize algorithm. Hyperopt will select its parameter automatically. Please refer the code below:
Figure 7
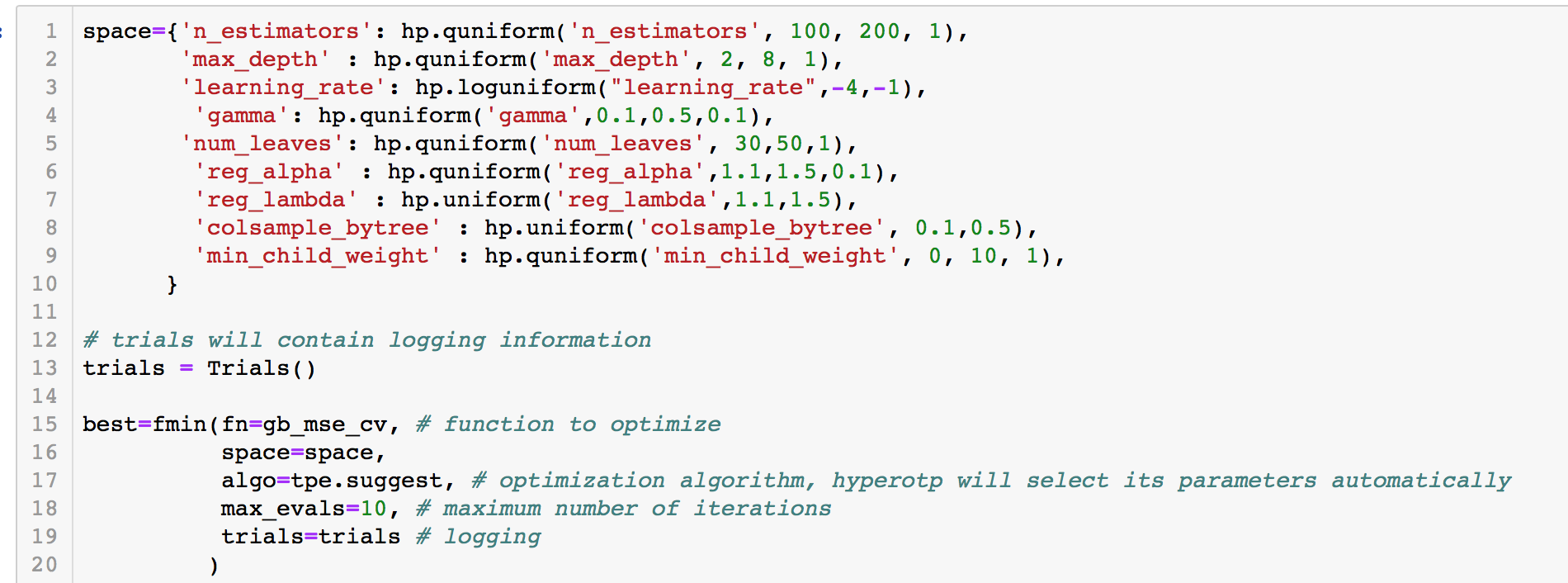
Now we can retrain our XGboost algorithm with these best params, and we are done.
Figure 7

Conclusion
Running the above gives us pretty good hyperparams for our learning algorithm. And that saves me a lot of time to think about various other hypotheses and testing them.
I tend to use this a lot while tuning my models. From my experience, the most crucial part in this whole procedure is setting up the hyperparameter space, and that comes by experience as well as knowledge about the models.
So, Hyperopt is an awesome tool to have in your repository but never neglect to understand what your models does. It will be very helpful in the long run.